Wat is een noindex tag? Als je pagina’s goed zichtbaar wilt maken in Google, is indexatie in Google natuurlijk onmisbaar. Pagina’s die niet geïndexeerd zijn in Google, maken simpelweg geen kans om vertoond te worden in de zoekresultaten van Google. Dit niet indexeren kan gebeuren zonder dat je dit wilt, maar je kunt dit ook aangeven dat je wilt dat je pagina’s niet geïndexeerd worden. Dit aangeven gebeurd door de noindex tag. In dit artikel vertellen we je meer over deze tag.
Het is soms strategisch om bepaalde content buiten de index van Google te houden. Hier komt de zogeheten noindex tag om de hoek kijken.

Waarom pagina op noindex?
Wanneer gebruik je een noindex tag op je website? Typische situaties wanneer je een noindex tag gebruikt zijn op pagina’s zoals bedankpagina’s of testomgevingen.
Waarom pagina op noindex? De noindex tag is vooral nuttig voor pagina’s die functioneel zijn, maar niet informatief voor bezoekers via Google. Denk hierbij dus aan:
- Bedankpagina’s na het invullen van een formulier
- Testomgevingen voor ontwikkelaars
- Pagina’s voor interne zoekresultaten
- Filterpagina’s binnen webshops
Maar waarom zet je deze dan op noindex? Deze pagina’s kunnen een negatieve invloed hebben op de SEO-waarde van de website als ze wel geïndexeerd worden, omdat ze bijvoorbeeld niet SEO-optimaal zijn gemaakt of geen toegevoegde waarde bieden aan het hoofdonderwerp van de website.
Een bedankpagina is bijvoorbeeld een onderdeel van je sales flow, maar heeft echt 0 toegevoegde waarde voor Google. Daarnaast wil je ook niet dat mensen deze pagina kunnen vinden in Google, omdat je op deze pagina bijvoorbeeld een speciale actie promoot die alleen is voor mensen die een bepaalde actie hebben ondernomen op je website.
Noindex om onderwerp duidelijk te houden
Door irrelevante of lage kwaliteit contentpagina’s uit de index te houden, voorkom je ‘focus spreiding’. Je zorgt dat alleen sterke, goed geoptimaliseerde pagina’s de aandacht krijgen van Google.
Zo zorg je ervoor dat elke pagina die Google ziet, dus een pagina is van hoge kwaliteit (in de ogen van Google). Zo is de crawler dus elke keer ‘tevreden’ wanneer de crawler jouw website bezoekt.
Dit versterkt de autoriteit van je belangrijkste content. Zeker in tijden waarin AI-gegenereerde content toeneemt en Google steeds meer content moet crawlen, is het belangrijk om strategisch om te gaan met wat je wel en niet laat indexeren.
Met noindex kan Google echter wel nog steeds je pagina crawlen, maar niet meer indexeren.
De rol van Google in het indexatieproces
Google gebruikt crawlers zoals Googlebot om websites te bezoeken en content te beoordelen. Alleen pagina’s die door deze crawlers gevonden en toegestaan zijn, worden toegevoegd aan de Google-index. Daarbij speelt het correct inzetten van technische signalen zoals een noindex tag een belangrijke rol. Deze tag bepaalt letterlijk of een pagina wel of niet mag worden opgenomen in de zoekresultaten van Google.
Definitie van een noindex tag
Metatag en http-header uitgelegd
Een noindex tag is dus een regel die je toevoegt aan een pagina, waarmee je tegen Google zegt: “deze pagina mag niet in de index verschijnen.” Er zijn twee hoofdvormen:
1. Metatag in de HTML:
<meta name=”robots” content=”noindex”>
Deze plaats je in het <head> gedeelte van de HTML-pagina. Dit is geschikt voor HTML-pagina’s.
2. http-header via X-Robots-Tag:
X-Robots-Tag: noindex
Deze gebruik je vooral voor niet-HTML-bestanden zoals PDF’s, afbeeldingen of video’s. De instructie wordt dan meegegeven via de server respons.
Belangrijk: de pagina moet toegankelijk zijn voor de crawler. Als je deze ook hebt uitgesloten in het robots.txt bestand, dan ziet Google de noindex instructie niet. Dit zorgt ervoor dat de pagina toch kan worden opgenomen in Google, bijvoorbeeld via externe links.

Hoe werkt een noindex tag technisch?
HTML implementatie via meta tag
Bij HTML-bestanden voeg je de noindex instructie toe in het <head> gedeelte. Dit doe je met de volgende regel code:
<meta name=”robots” content=”noindex”>
Je kunt ook kiezen voor index (standaard), dofollow (standaard) of noindex, nofollow, afhankelijk van of je wilt dat Google de links op de pagina wel of niet volgt. Maar let op: uit recente documentatie van Google blijkt dat Google links op een noindex-pagina na verloop van tijd toch niet meer volgt – ook niet als je follow, hebt ingesteld (dit is dus standaard).
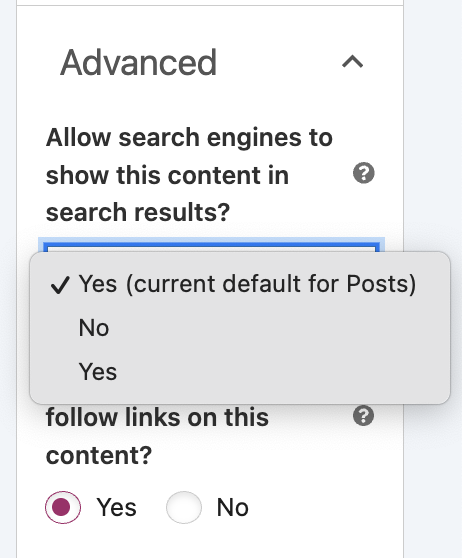
Dingen aanpassen in de code van je website zou je niet moeten doen als je hier geen ervaring mee hebt. Gelukkig bestaan er in veel websitebouwers (zoals WordPress) plug-ins voor. Hoe stel je noindex in, in WordPress? In een tool zoals WordPress hoef je zelf niet in de <head> dingen aan te passen. Met plug-ins zoals RankMath of Yoast kun je makkelijk pagina’s op noindex zetten.
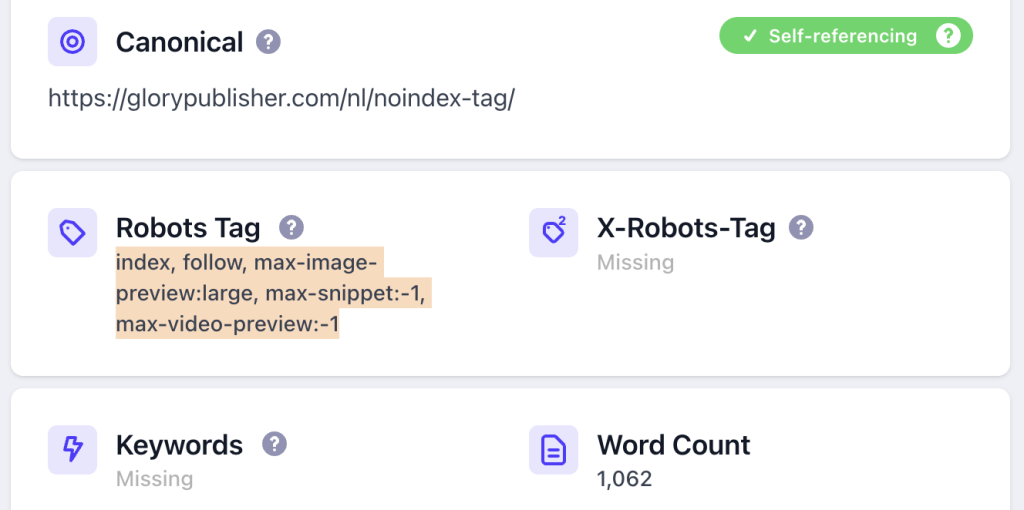
Hoe kun je zien of een pagina op noindex staat?
Een makkelijke en niet technische manier om te bekijken of een pagina op noindex staat, is door een Chrome extensie te gebruiken zoals: Detailed SEO extension. Hiermee kun je al de robots tags zien van een pagina, dus ook of de pagina op index of noindex staat.